

Unit Tests. Why Testable Code Matters? (Part 1)
by QArea Expert on Jan 21, 2016
Unit testing is an indispensable part of any good programmer’s toolkit. Creating a robust unit test comes across often as a challenging task, though. Developers are often misled by the thought that unit testing is tough because they don’t have enough testing knowledge or they are not aware of some secret testing techniques and methods. I am going to show you that writing unit tests is simple. The real challenge is writing an easily testable code. A poorly-written code creates a lot of problems and increases expenditures. I will hone in on what it takes to write a good, testable code, what practices should be avoided and what should be paid more attention to. The key objective is to write the code which will be cleaner and more maintainable, not only more testable.
What is a Unit Test?
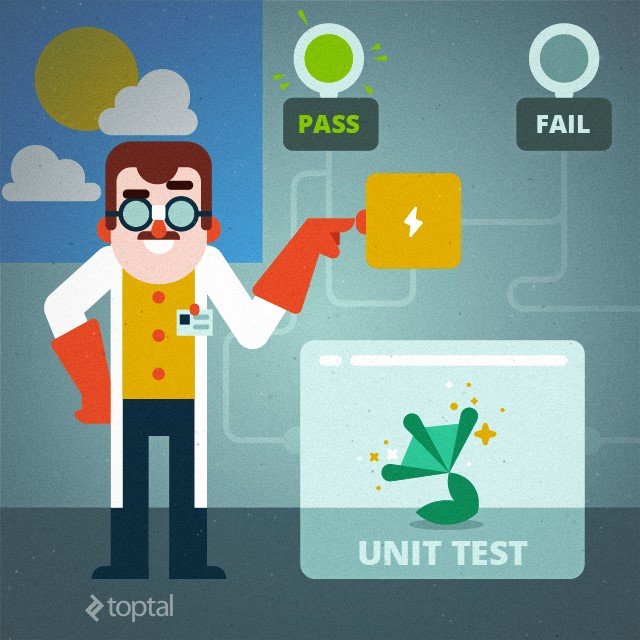
A unit test is the smallest testable code of an application which is verified separately and independently from other portions of code. Usually unit testing consists of 3 stages. First, it starts a small part of an app (called SUT, or system under test). This phase is known as Arrange. Then an input is given to a unit. It is called Act. And the final phase is receiving the response and verifying if it corresponds to the expected output data. This phase is called Assert. There are two key types of unit testing: state-based (verifying if the output data are correct) and interaction-based (verifies that SUT calls certain methods properly).
A good unit test can be compared to a hybrid creature, created by a crazy scientist, with bird wings, frog legs, octopus tentacles and a dog’s head. This chimera is very similar to the work of programmers. To ensure every part of the creature works as it should, a mad scientist would send an electrical stimulus to a given part and check how it works. That is the same as Arrange- Act- Assert scenario of the unit test.
I will use C# for all examples in this article, but the concepts described apply to all object-oriented programming languages.
A simple unit test could look like this:
[TestMethod]
public void IsPalindrome_ForPalindromeString_ReturnsTrue()
{
// In the Arrange phase, we create and set up a system under test.
// A system under test could be a method, a single object, or a graph of connected objects.
// It is OK to have an empty Arrange phase, for example if we are testing a static method -
// in this case SUT already exists in a static form and we don't have to initialize anything explicitly.
PalindromeDetector detector = new PalindromeDetector();
// The Act phase is where we poke the system under test, usually by invoking a method.
// If this method returns something back to us, we want to collect the result to ensure it was correct.
// Or, if method doesn't return anything, we want to check whether it produced the expected side effects.
bool isPalindrome = detector.IsPalindrome("kayak");
// The Assert phase makes our unit test pass or fail.
// Here we check that the method's behavior is consistent with expectations.
Assert.IsTrue(isPalindrome);
}
How Unit Tests and Integration Tests Differ
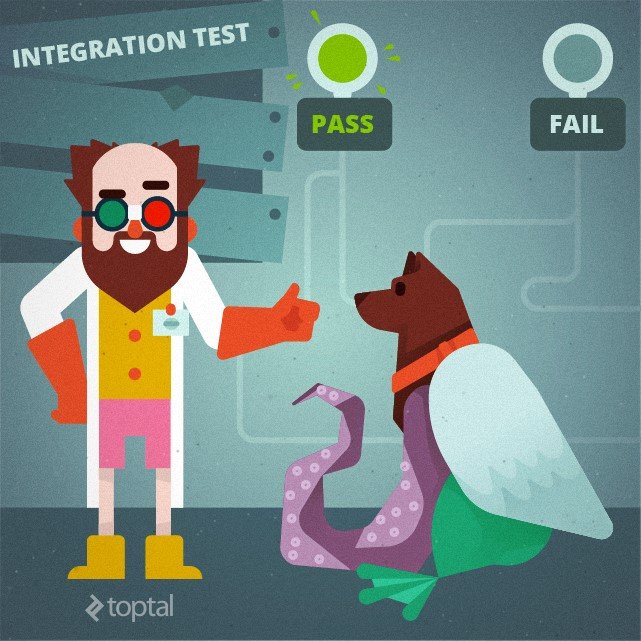
We will focus now on how unit tests and integration tests differ. Unit test checks how a unit (the smallest testable part of an app) responds to the stimulus, while the objective of integration tests is to verify that all parts of an app function properly together and are compatible with the real-life environment. They are usually quite complex and call for using web servers and databases.
A unit test checks how a unit functions isolated from other units and from the environment. Integration test is a much more complex process. It checks how different parts of an application work together in a real-life environment.
To ensure all the units perform correctly, both individually and in interaction with the others, unit and integration tests are to be combined sensibly. We have to always understand whether we are implementing unit tests or integration tests.
If we are designing a unit test to test a unit in a particular environment, then this is not a unit test anymore. The difference can be often misleading. If we are writing to verify some subtle edge case in a business logic class, and it occurs to us that it calls for external resources like web services or databases, something is wrong with our unit test and with its design.
What are the attributes of a good unit test?
- Easy to write many unit tests covering multiple test scenarios.
- Easy to read. A good unit test should be clear and readable.
- Good unit cases should be reproducible and independent from the environment.
- Slow test cases will incredibly slow down the process.
- The difference between a unit test and an integration test should be clear. What concerns unit tests, no external resources should be involved. Unit tests and Integration tests have completely different objectives.
Testable VS Untestable Code
The code should be written in the way that it is easy to write a unit test for it and test it for defects.
Here are the main bad practices you need to avoid (What bad practices can prevent you from writing a good code).
Contaminating the Code with Non-deterministic Factors
Let’s consider a simple example. You are making a program for a smart microcontroller. And it should turn on the light automatically if any movements are spotted in the evening or at night. Here is a method returning a string representation indicating the time of the day (“Night”, “Morning”, “Afternoon” or “Evening”).
public static string GetTimeOfDay()
{
DateTime time = DateTime.Now;
if (time.Hour >= 0 && time.Hour < 6)
{
return "Night";
}
if (time.Hour >= 6 && time.Hour < 12)
{
return "Morning";
}
if (time.Hour >= 12 && time.Hour < 18)
{
return "Afternoon";
}
return "Evening";
}
A proper state-based unit test for this method can’t be written because of those non-deterministic factors which will differ during program execution, and the results will differ too.
If there is any non-deterministic behavior, it makes it impossible to test internal logic of the unit. In this case the test won’t be a unit test, it would be a hybrid, mixed with an integration test. It would be more costly and less reliable because using external resources, such as databases and web services would be involved.
Let’s look at how we need to run this test:
[TestMethod]
public void GetTimeOfDay_At6AM_ReturnsMorning()
{
try
{
// Setup: change system time to 6 AM
...
// Arrange phase is empty: testing static method, nothing to initialize
// Act
string timeOfDay = GetTimeOfDay();
// Assert
Assert.AreEqual("Morning", timeOfDay);
}
finally
{
// Teardown: roll system time back
...
}
}
All the testability problems stem from bad API. In its present state, this method contains the following problematic issues:
- It is closely related to the particular data source. It depends too much on the particular data source.
- It is hard to maintain.
- It doesn’t reveal the whole truth about what is required to perform its work.
- Breaking the Single Responsibility Principle.
The effectivity of the following methods has been tested by the experience of our experts in QArea. Now let’s look at how we can fix the low quality API:
Fixing the API with a Method Argument
The simplest way to remedy the API is to introduce a Method Argument.
public static string GetTimeOfDay(DateTime dateTime)
{
if (dateTime.Hour >= 0 && dateTime.Hour < 6)
{
return "Night";
}
if (dateTime.Hour >= 6 && dateTime.Hour < 12)
{
return "Morning";
}
if (dateTime.Hour >= 12 && dateTime.Hour < 18)
{
return "Noon";
}
return "Evening";
}
The method demands the caller to provide a Date Time argument and not spy for it by itself. This will ensure good unit testing, since the method is now deterministic and its result is now predefined by the input.
All the API problems (such as tight coupling, SRP violation, not easily understandable API) were solved with simple refactoring.
Ok, the method is testable. But what about the clients? Now it is the responsibility of the caller to provide date and time to the GetTimeOfDay method. And if we are not attentive enough, they can become untestable. Let’s talk about how we can fix it.
Fixing the Client API with a Dependency Injection.
Imagine we continue working on the smart microcontroller code, which has to turn the light on and off depending on the time of day and movement detection.
public class SmartHomeController
{
public DateTime LastMotionTime { get; private set; }
public void ActuateLights(bool motionDetected)
{
DateTime time = DateTime.Now; // Ouch!
// Update the time of last motion.
if (motionDetected)
{
LastMotionTime = time;
}
// If motion was detected in the evening or at night, turn the light on.
string timeOfDay = GetTimeOfDay(time);
if (motionDetected && (timeOfDay == "Evening" || timeOfDay == "Night"))
{
BackyardLightSwitcher.Instance.TurnOn();
}
// If no motion is detected for one minute, or if it is morning or day, turn the light off.
else if (time.Subtract(LastMotionTime) > TimeSpan.FromMinutes(1) || (timeOfDay == "Morning" || timeOfDay == "Noon"))
{
BackyardLightSwitcher.Instance.TurnOff();
}
}
}
Input problem is that it is on a higher abstraction level. Another argument can be introduced, again passing the responsibility of providing a DateTime value to the caller of a new method with signature ActuateLights(bool motionDetected, DateTime dateTime).
Inversion of Control is easy but very helpful for code decoupling. Instead of taking the issue to a higher level, another technique can be employed to keep both ActuateLights(bool motionDetected) method and its clients testable: Inversion of Control, or IoC.
The key here is to separate desicion-making code from action code. This boosts flexibility, increases modularity of the code and facilitates decoupling of the components.
There are different ways in which IoC (Inversion of Control) can be implemented. For instance, dependency injection using a constructor and how it can aid in building a testable SmartHomeController API.
The first step is to make an IDateTimeProvider interface, which contains a method signature for retrieving some date and time:
public interface IDateTimeProvider
{
DateTime GetDateTime();
}
Refer SmartHomeController to an IDateTimeProvider implementation, and pass it the responsibility of receiving date and time:
public class SmartHomeController
{
private readonly IDateTimeProvider _dateTimeProvider; // Dependency
public SmartHomeController(IDateTimeProvider dateTimeProvider)
{
// Inject required dependency in the constructor.
_dateTimeProvider = dateTimeProvider;
}
public void ActuateLights(bool motionDetected)
{
DateTime time = _dateTimeProvider.GetDateTime(); // Delegating the responsibility
// Remaining light control logic goes here...
}
}
This explains why Inversion of Control is called so.The control of what mechanism to use for reading date and time was inverted, and now belongs to the client of SmartHomeController, not SmartHomeController itself. Thereby, the execution of the ActuateLights(bool motionDetected) method fully depends on two things that can be easily handled from the outside: the motionDetected argument, and a specific implementation of IDateTimeProvider, passed into a SmartHomeController constructor.
Why is this significant for testing? It means that different IDateTimeProvider implementations can be used in production code and unit test code. In the production environment, some real-life implementation will be injected (e.g., one that reads actual system time). In the unit test, a “fake” implementation can be injected returning a constant or predefined DateTime value suitable for testing the particular scenario.
A fake implementation of IDateTimeProvider would look like this:
public class FakeDateTimeProvider : IDateTimeProvider
{
public DateTime ReturnValue { get; set; }
public DateTime GetDateTime() { return ReturnValue; }
public FakeDateTimeProvider(DateTime returnValue) { ReturnValue = returnValue; }
}
Using this class we can isolate SmartHomeController from non-deterministic factors and run a state-based unit test.We are going to check that, if motion was detected, the time of that motion is recorded in the LastMotionTime property:
[TestMethod]
void ActuateLights_MotionDetected_SavesTimeOfMotion()
{
// Arrange
var controller = new SmartHomeController(new FakeDateTimeProvider(new DateTime(2015, 12, 31, 23, 59, 59)));
// Act
controller.ActuateLights(true);
// Assert
Assert.AreEqual(new DateTime(2015, 12, 31, 23, 59, 59), controller.LastMotionTime);
}
It wouldn’t have been possible to run this test before refactoring. Now that we’ve got rid of non-deterministic factors and checked if the state-based scenario works well, do you think SmartHomeController can be fully tested?
Contaminating the Codebase with Side Effects.
Although the issues caused by the non-deterministic hidden input have been resolved, and some functionality was successfully tested, some amount of the code still can’t be tested. Let’s look through the following part of the ActuateLights(bool motionDetected) method which is to turn the light on or off.
// If motion was detected in the evening or at night, turn the light on.
if (motionDetected && (timeOfDay == "Evening" || timeOfDay == "Night"))
{
BackyardLightSwitcher.Instance.TurnOn();
}
// If no motion was detected for one minute, or if it is morning or day, turn the light off.
else if (time.Subtract(LastMotionTime) > TimeSpan.FromMinutes(1) || (timeOfDay == "Morning" || timeOfDay == "Noon"))
{
BackyardLightSwitcher.Instance.TurnOff();
}
SmartHomeController passes the responsibility of turning the light on or off to a BackyardLightSwitcher object, which implements a Singleton pattern. What are the faults of this design?
The combination of interaction-based testing and unit-based testing should be carried out to unit test the ActuateLights(bool motionDetected) method. This means that we should ensure that methods for turning the light on or off aren’t called unless appropriate conditions are met. The present design won’t let us do that. The TurnOn() and TurnOff() methods of BackyardLightSwitcher cause some state changes in the system and lead to side effects. If we want to check that these methods were called is to check whether their corresponding side effects occurred or not, which can be problematic.
Imagine the motion sensor, backyard lantern, and smart home microcontroller are combined into the network of Internet of Things and communicate via wireless protocol. Then a unit test can try to obtain and carry out the analysis of the network traffic. If the hardware components are connected via a wire, the unit test can verify whether the voltage was applied to the appropriate electrical circuit. Or, after all, it can verify if the light switched on or off with the help of another light sensor.
Unit testing side-effecting methods could be as difficult as unit testing non-deterministic ones and even turn out infeasible. The resulting test will be challenging to run, unreliable, slow, and not pure unit test.
The reason for all the testability issues is the bad API of the very code, not that the developer can’t write solid unit tests. The way how the light sensing is put into action doesn’t really matter, the SmartHomeController API get affected by the following problems.
- Tight coupling with the specific way of implementation. The API depends on the embedded instance of BackyardLightSwitcher. ActuateLights(bool motionDetected) method is impossible to be reused, to switch any light other than the one in the backyard.
- It breaks the Single Responsibility Principle. There are two reasons for the API to change. The first one is when changes are introduced to the internal logic (such as choosing to make the light turn on only at night, but not in the evening) and the second one, if the light-turning mechanism is replaced with a different one.
- It doesn’t tell the truth about its dependencies, there is no way for developers to know that SmartHomeController depends on the hard-coded BackyardLightSwitcher component, other than looking into the source code.
- It is not easily understandable and maintainable. What are we to do if the light won’t turn on when all conditions are met? We could waste a lot of time unsuccessfully attempting to repair the SmartHomeController because the problem was caused by a defect in the BackyardLightSwitcher or a burned out light bulb.
Decoupling of components can solve both testability problems and bad API. As with the previous example, Dependency Injection would solve these issues; just add an ILightSwitcher dependency to the SmartHomeController, pass it the responsibility of turning the light switch, and pass a test ILightSwitcher implementation that will record whether the right methods were called under the right conditions. Let’s look through an interesting alternative approach for separating the responsibilities.
How to fix the API: Higher-Order Functions
This approach is an option in any object-oriented language that supports first-class functions. Let’s take advantage of C#’s functional features and make the ActuateLights(bool motionDetected) method accept two more arguments: a pair of Action delegates, pointing to methods that should be called to turn the light on and off. This solution will convert the method into a higher-order function:
public void ActuateLights(bool motionDetected, Action turnOn, Action turnOff)
{
DateTime time = _dateTimeProvider.GetDateTime();
// Update the time of last motion.
if (motionDetected)
{
LastMotionTime = time;
}
// If motion was detected in the evening or at night, turn the light on.
string timeOfDay = GetTimeOfDay(time);
if (motionDetected && (timeOfDay == "Evening" || timeOfDay == "Night"))
{
turnOn(); // Invoking a delegate: no tight coupling anymore
}
// If no motion is detected for one minute, or if it is morning or day, turn the light off.
else if (time.Subtract(LastMotionTime) > TimeSpan.FromMinutes(1) || (timeOfDay == "Morning" || timeOfDay == "Noon"))
{
turnOff(); // Invoking a delegate: no tight coupling anymore
}
}
This is a more functional-flavored solution than the classic object-oriented Dependency Injection approach; however, it gives us the same result with less code, and more expressiveness, than Dependency Injection. It is no longer necessary to implement a class that conforms to an interface in order to supply SmartHomeController with the required functionality; instead, we can just pass a function definition. Higher-order functions can be considered as another way of implementing Inversion of Control.
Now, to run an interaction-based unit test of the resulting method, we can pass easily verifiable fake actions into it:
[TestMethod]
public void ActuateLights_MotionDetectedAtNight_TurnsOnTheLight()
{
// Arrange: create a pair of actions that change boolean variable instead of really turning the light on or off.
bool turnedOn = false;
Action turnOn = () => turnedOn = true;
Action turnOff = () => turnedOn = false;
var controller = new SmartHomeController(new FakeDateTimeProvider(new DateTime(2015, 12, 31, 23, 59, 59)));
// Act
controller.ActuateLights(true, turnOn, turnOff);
// Assert
Assert.IsTrue(turnedOn);
}
This way SmartHomeController API has been made fully testable. And now it is possible to run both state-based and interaction-based unit tests for it. This helped to enhance testability, decoupling and made the API better and more reusable.
To ensure full unit test coverage, a number of similar tests can be executed to check all possible cases. This won’t be a hard task because unit tests are now quite simple to run. That is the idea proven by experience and shared by specialists of our software development company.
Don’t miss out on the second part of the article, featuring other crucial problems of untestable code and their effective solutions. Subscribe to our updates and we will send it to you as soon as it comes out.
Source: Toptal.com
We Help With
Your tech partner needs to be well versed in all kinds of software-related services. As the software development process involves different stages and cycles, the most natural solution is to have them all performed by the same team of experts. That’s exactly what our diverse range of services is for.
The choice of technology for your software project is one of the defining factors of its success. Here at QArea, we have hands-on experience with dozens of popular front-end, back-end, and mobile technologies for creating robust software solutions.
In-depth familiarity and practical experience with key technologies are one of the cornerstones of successful software development and QA. But it also takes specific knowledge of the industry to develop a solution that meets the expectations of the stakeholders and propels its owner to success.


Ensure an effective online presence for your business with a corporate site.



















